
Blogger discovers this cool thing called “RSS”.
Shot out to freshness, been using that for years! Self hosting it
FreshRSS for those playing along at home…
I did this too recently. Highly recommend.
I am using RSS and I love it
I just saw this article last week! I love RSS feeds and set up a bunch through my work email outlook client. They been there since like 2010 (yes I still have the same job…) and I barely touch them these days due to time, and some sites died, but it’s still the quickest way to catch up on the news you want. Wherever I saw this posted last I saw a recommend for FeedFlow and have been messing with that phone app to try and make some ultimate new feed for myself.
Wait until I show them my PHP BB.
The problem I run into is most news sites optimize for 2 things
- Getting on google
- Getting linked on Twitter or Reddit
So most sites have a fuck ton of noise and carpet bomb ads.
I’d love to go back to the RSS model but it’s hard finding sites worth reading again.
This is why I legit built my own space news app , because my autistic brain can’t handle all the crap they’ve added to pages. I just need the text, and images. I don’t need links to other articles in the body of the article! I’m currently reading this article!! and stop citing your own articles as sources!
Find one or two sites you regularly like from your usual sources. Then when THOSE sources link to another source, FOLLOW that link. If that site has good content, add it to your list.
It doesn’t take long to build a solid RSS feed, just need to spend a little time curating it. The key is to pay attention to who is providing the info.
Don’t like the direction a site is going, remove it from your feed.
If you see that one source is commonly the original source for information, or reporting make sure you do what you can to support it. Do they have a patreon? Can you share it out to your other sources?
Also, make sure you’re not falling into a bubble, follow national and international news sources.
I’d love to take a look at what other people are following and what they like about it. My own followed are kind of random.
Maybe this is one of those Qs a simple web search can answer…
Really hoping I don’t dox myself with this…
I (tried to) remove all the local news sites, but this gives me a pretty decent overview of things I’m interested in, without being overwhelming. You should be able to find some local news sources, and add their LOCAL only feed, so you don’t get hammered with national and international news.
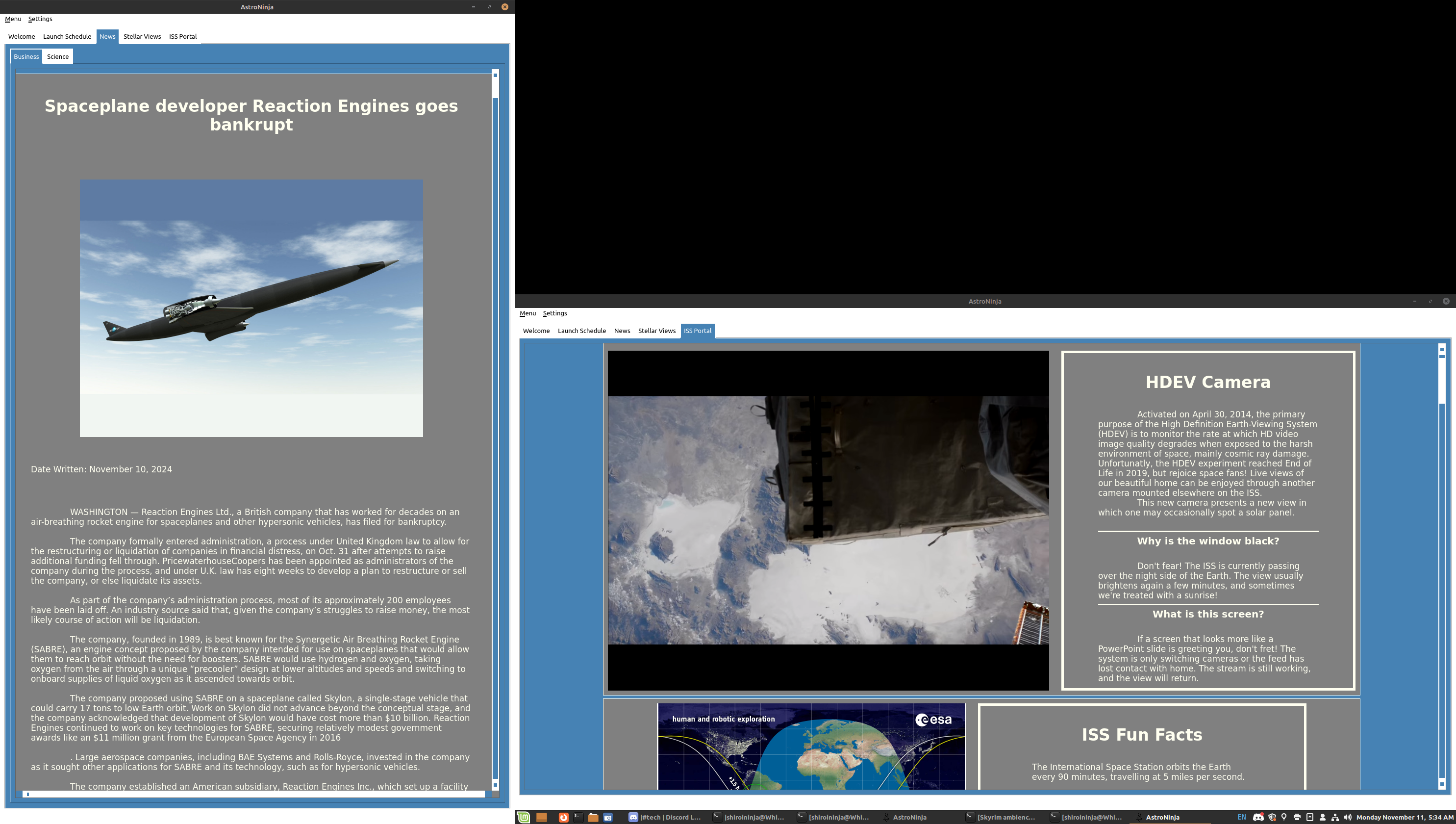
<outline text="ADHDinos" type="rss" xmlUrl="https://www.webtoons.com/en/challenge/adhdinos/rss?title_no=820817" htmlUrl="https://www.webtoons.com/en/canvas/adhdinos/list?title_no=820817" description="A webcomic about ADHD and the difficulties I've encountered through it. *No permission required for reposts*"/> <outline text="Humon Comics" type="rss" xmlUrl="http://feeds.feedburner.com/Humon-Comics" htmlUrl="http://humoncomics.com" description="The latest issues."/> <outline text="Order of the Stick" type="rss" xmlUrl="https://www.giantitp.com/comics/oots.rss" htmlUrl="http://www.giantitp.com/Comics.html" description="Order of the Stick"/> <outline text="War and Peas" type="rss" xmlUrl="https://warandpeas.com/feed/" htmlUrl="https://warandpeas.com/" description="Funny Comics"/> <outline text="Wondermark" type="rss" xmlUrl="https://wondermark.com/feed/" htmlUrl="https://wondermark.com/" description="An Illustrated Jocularity."/> <outline text="XKCD" type="rss" xmlUrl="https://xkcd.com/atom.xml" htmlUrl="https://xkcd.com/"/> <outline text="AnandTech" type="rss" xmlUrl="https://www.anandtech.com/rss/" htmlUrl="https://www.anandtech.com" description="This channel features the latest computer hardware related articles."/> <outline text="Ars Technica" type="rss" xmlUrl="https://feeds.arstechnica.com/arstechnica/index" htmlUrl="https://arstechnica.com" description="Serving the Technologist since 1998. News, reviews, and analysis."/> <outline text="BleepingComputer" type="rss" xmlUrl="https://www.bleepingcomputer.com/feed/" htmlUrl="https://www.bleepingcomputer.com/" description="BleepingComputer - All Stories"/> <outline text="Bloody Disgusting!" type="rss" xmlUrl="http://feeds.feedburner.com/BloodyDisgusting" htmlUrl="https://bloody-disgusting.com/" description="Horror movie news, reviews, interviews, videos, podcasts and more"/> <outline text="Deeplinks" type="rss" xmlUrl="https://www.eff.org/rss/updates.xml" htmlUrl="https://www.eff.org/rss/updates.xml" description="EFF's Deeplinks Blog: Noteworthy news from around the internet"/> <outline text="iFixit" type="rss" xmlUrl="https://www.ifixit.com/News/rss" htmlUrl="https://valkyrie.ifixit.com" description="Fixing the world, one gizmo at a time."/> <outline text="Krebs on Security" type="rss" xmlUrl="https://krebsonsecurity.com/feed/" htmlUrl="https://krebsonsecurity.com" description="In-depth security news and investigation"/> <outline text="NPR Topics: News" type="rss" xmlUrl="https://feeds.npr.org/1001/rss.xml" htmlUrl="https://www.npr.org/templates/story/story.php?storyId=1001" description="NPR news, audio, and podcasts. Coverage of breaking stories, national and world news, politics, business, science, technology, and extended coverage of major national and world events."/> <outline text="Schneier on Security" type="rss" xmlUrl="https://www.schneier.com/feed/atom/" htmlUrl="https://www.schneier.com"/> <outline text="Science & Health – FiveThirtyEight" type="rss" xmlUrl="https://fivethirtyeight.com/science/feed/" htmlUrl="https://fivethirtyeight.com" description="FiveThirtyEight uses statistical analysis — hard numbers — to tell compelling stories about elections, politics and American society."/> <outline text="The 19th" type="rss" xmlUrl="https://19thnews.org/feed/" htmlUrl="https://19thnews.org/" description="The 19th is an independent, nonprofit newsroom reporting at the intersection of gender, politics and policy."/> <outline text="Universe Today" type="rss" xmlUrl="https://www.universetoday.com/feed/" htmlUrl="https://www.universetoday.com/" description="Space and astronomy news"/>Omg thank you for sharing. I think you’re good re doxxing, the only one that looked iffy was that Ars Technica URL, and I did a thorough check and couldn’t find any PII or credentials leaking.
My own feed is pretty pathetic (had to reinstall OS and ofc didn’t back up the past 5 years):
<outline text="RSS" title="RSS" type="rss" xmlUrl="http://edunham.net/rss.html"/> <outline text="thefoolwithapen" title="thefoolwithapen" type="rss" xmlUrl="https://thefoolwithapen.com/index.xml" htmlUrl="https://thefoolwithapen.com/"/> <outline text="Wikipedia Atom feed" title="Wikipedia Atom feed" type="rss" xmlUrl="https://en.wikipedia.org/w/index.php?title=Special%3ARecentChanges&%3Bfeed=atom" htmlUrl="https://en.wikipedia.org/wiki/Special:RecentChanges"/> <outline text="Tech News weekly bulletin feed" title="Tech News weekly bulletin feed" type="rss" xmlUrl="https://meta.wikimedia.org/w/api.php?action=featuredfeed&%3Bfeed=technews&%3Bfeedformat=rss" htmlUrl="https://meta.wikimedia.org/wiki/Special:MyLanguage/Main_Page"/> <outline text="PedalPC" title="PedalPC" type="rss" xmlUrl="https://www.pedalpc.com/rss.xml" htmlUrl="https://www.pedalpc.com/"/>I also don’ think I’m following Wikipedia correctly. I don’t think I’ve ever managed to figure it out :/
Thanks, I updated the Ars one to a generic feed. Shoulda caught that.
Yeah, is there some sort of directory or something? That’d be cool.
I really agree - I’ve stepped away from reading so much of what’s online because it’s all clickbaity junk with no substance. I’m not sure where to look for actual content to put in my reader. But I’m making forays.
On Firefox on Android there is a reader mode that gives you just the text and images. It’s the little icon next to the url. Sometimes you can bypass a paywall if you press it really quick before the page finishes loading.
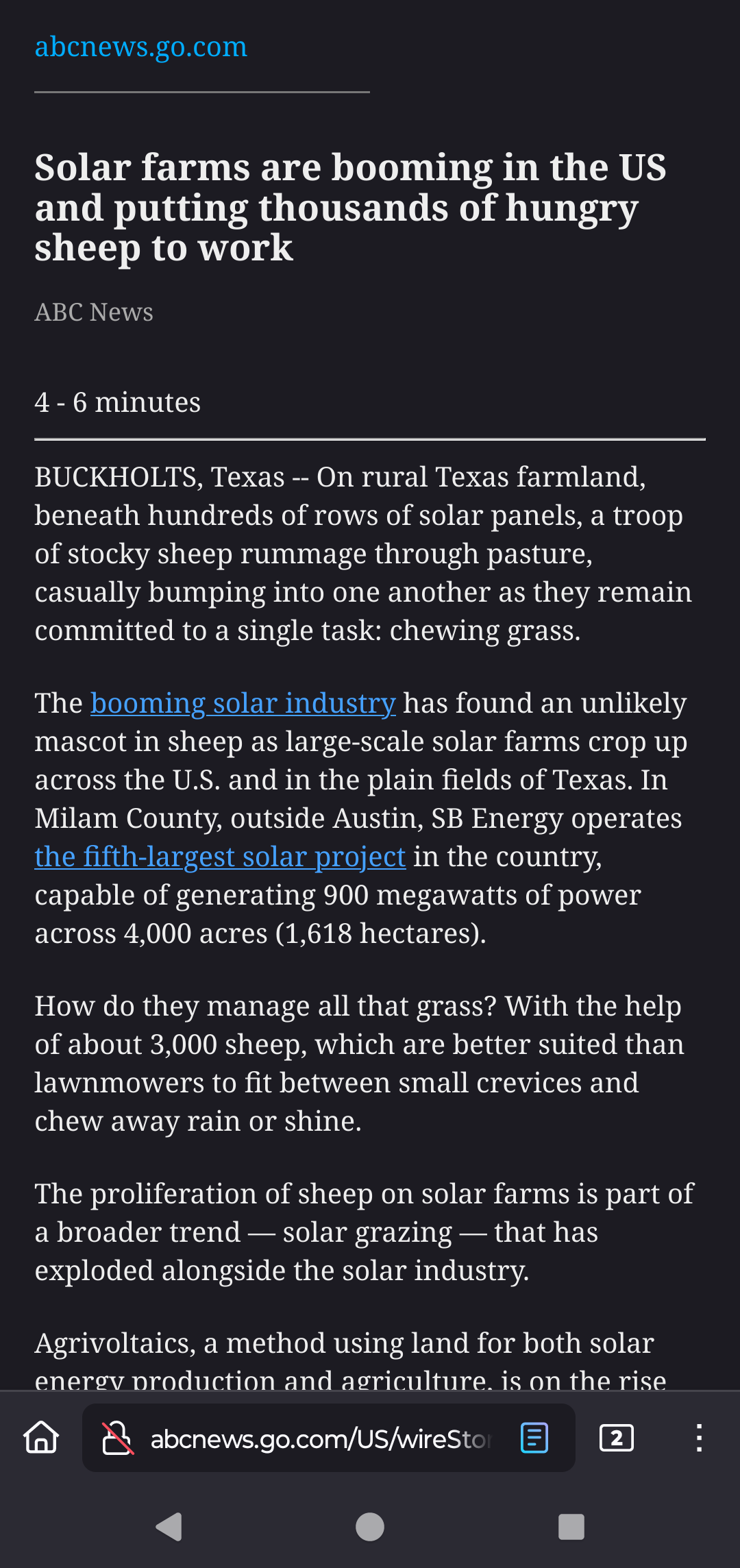
I use it quite often. Chills the eyes when reading. Standardized font(size) and design make this bearable.
Lemme clarify a bit. I love reader mode too and agree it cuts out a lot of cruft.
My point was that authors and articles spend less time trying to write an engaging article and more time trying to shove SEO keywords and questions into articles. It ruins the article and makes it something not worth reading.
Reader mode is great but if the substance isn’t there then it’s all for naught.
I’ve been interested in trying out RSS again but I don’t want to self-host. Can anyone recommend a RSS client (hosted, local, or whatever) that they like?
FreshRSS is nice. You can hook into any client you want on android/ios/etc… or use theirs. Reminds me of google reader and some others. This is what it looks like:

I have mine selfhosted. Pretty easy on yunohost, docker, or other sites. Looks like they have a couple of servers out there if you dont want to self host: https://freshrss.org/cloud-providers.html
If you’re on iOS, feeeed is kinda slick :)
I needed this, thanks! For the lazy, it’s here.
I used Feedly since Google Reader was shut down. Then 1.5 years ago, as Feedly was getting more paywalls and AI-crap, I switched to Newsblur, and have been a happy user ever since. I love its Intelligence Trainer that lets me hide posts with certain tags/authors/keywords.
Unlimited hosted-by-them Newsblur costs 36 USD / year. It has a FLOSS version and a more limited free hosted-by-them version, but the 2.5 GBP / month was worth the QoL increase for me.
I prefer the Feedbro browser extension in Firefox. I think it is available for chrome/edge as well.
Thunderbird has RSS integrated, which could be quite neat once that synchronizes.
I’ve had some decent times with inoreader.
inoreader seems very ergonomic, thanks!
On android i like ReadYou on fdroid
It can be as simple as just putting an app on your phone. I use feeder which is fine. Pretty bare bones, but in that way it’s easy to learn and use.
I’ve also been meaning to try out an app called Nunti, which I heard about a while ago from this Lemmy post. It claims to be an RSS reader with the added benefit of an (open source and fully local) algorithm to provide some light curation of your feed. It looks interesting, but I haven’t actually tried it out yet because I’m still deciding whether I want any algorithm curating my feed, even one as transparent as Nunti’s. It’s also only available through F-Droid right now, which is a bit of a barrier to entry.
If it’s open source, you could perhaps tinker with the algorithm. My main desires for rss feeds are:
- a way to filter out fluff affiliate link articles (e.g., 8 best gadgets on sale for prime day)
- a way to cluster articles on the same topic (i don’t really need to read 5 articles about the same news item)
Any clue if nunti could do that?
Newsblur can do the first kind of filtering. You select “best gadgets” in the title, and all posts on that feed with that phrase in the title will be hidden from then on.
Feeder can do keyword filtering on titles, but not on a per feed basis, and only with simple wildcards. I’ve been able to filter out a bit with it, though.
Man, I feel you on the affiliate link fluff. I actually ended up unsubscribing from the Popular Mechanics and Popular Science feeds because the signal to noise ratio was so bad.
The creator of Nunti provided a very good primer on the algorithm design here. Basically, you indicate to the app whether you like or dislike an article and then it does some keyword extraction in the background and tries to show you similar articles in the future. I suppose you might be able to dislike a bunch of the fluff and hope the filter picks up on it, but it isn’t really designed to support the kind of rules that would completely purge a certain type of content from your feed.
Oh wow, they really did a good job of explaining it. It’s not too complex. I think it probably would be able to filter out some of the fluff.
The fact that it’s only available through fdroid is actually a good thing in my opinion.
there are some publically available FreshRSS instances that you can make an account with, I personally use hostux. you can access it with the browser and any apps that support FreshRSS (in my case, Read You or Capy Reader on Android, and sometimes RSS Guard on desktop).
Wait until this guy gets to 2012, and discovers Flipboard…
Google Reader was my goto and when they killed that I tried a bunch of others and none quite hit the same. Gutted that one hit the Google graveyard.
Classic Embrace-Extend-Extinguish move.
Protip: Youtube channels have RSS feeds, they’re just buried in the source of the page. Ctrl-U and then Ctrl-F title=“RSS”
It’s in order if you only use the subscriptions tab too
A couple weeks ago I did a poll and it turns out almost 25% of the people who “watch YT daily or almost daily” don’t know about the subscriptions tab.
It’s so weird, but explains so many people claiming to not see new uploads. They only use the home page and never the actual subscriptions
Interesting, whenever I see the home page videos my soul dies a little. Couldn’t handle that regularly
The home page is fine for me, it’s dialed pretty well into my tastes. I always click the don’t reccommend channel or video if I don’t like a recommendation.
The Trending tab, on the other hand… Yikes.
I guess to get actual value from these videos you will still need to visit youtube.com though, in the end giving them valuable data to analyze.
You can play YouTube videos in VLC player
If I try to watch over a tor exit node (using tor anonymization technology). It shows me this message. They really want to know my IP-Address?
Sign in to confirm you’re not a bot This helps protect our community. Learn more
Maybe try one of the downloaders
I can recommend yt-dlp
Yeah but the goal here is to escape the algorithm deciding what you consume
good point, organic sharing is better than the addictive algorithm.
TIL. Gonna have to test this out my FreshRSS feed. Ty 🥰
You can also just drop the youtube channel link (ex. https://www.youtube.com/@LinusTechTips ) as well into most readers and it’ll sort it out for you, so you don’t even have to go digging.
I wrote my own rss reader for youtubue, so it does this digging for me when I paste in a channel link :)
Cool tip.
If you want news for a specific game and they release news on steam… all steam pages have an RSS feed.
Genuinely did not know that, thanks
Wow that’s really neat, thanks!
deleted by creator
never stopped using rss/atom with ttrss 💪
For iOS, this one doesn’t collect any data. It’s pretty barebones, but also free. It nags you a bunch at first but eventually stopped
NetNewsWire is the iOS and macOS app for RSS. It has been around since RSS started out and is now open source.
It doesn’t have keyword filters or at least I can’t find them.
My local news sites block RSS because they paywall all their articles to force you to buy a newspaper or pay twice as much for online access.
I skip the RSS and just buy the local paper.








